- Are static variables inherited by subclasses?
Static variables are inherited by sub classes. However are at class level instead of object level and there is just one. - Are static methods overridden by subclasses?
That depends. If the reference used to store the object is of the super type, the super types static method is invoked. This is because static is at class level. - What is the difference between a Set and a List?
In a set an object can only exist once. In a List the same object can be added many times. - Why should we use the @Override annotation?
We should use this to ensure compile time checking that the contract of a subclass is not broken by changes to the superclass. - What is the main difference between Callable interface and Runnable interface?
The main difference is that the call method on callable can return a typed result, that can be queried in the future. Callable also throws an exception. - Whats a covariant return?
A covariant return is allowed since Java 1.5 and means that a method can return a sub classed object of the return type. In Java 1.4 and earlier the return type had to match exactly. - What is an instance initialisation block? An instance initialisation block is run once after a new object is created. There can be as many of them in the class as you like, but they run in order declared from top to bottom in the class.
- Does an instance initialisation block run before or after the constructor?
They run after the call to super, but before the rest of the constructor. - What is auto boxing?
It's the ability in Java to automatically switch between the primitive type and the object, without a call to a converter method. - What is widening?
It's the ability of Java to find a method with the smallest, closest java type. For example if one method takes a long and another takes an int, if I pass a short - java will automatically "widen" the short and select the method that taken an int. - What is the difference between "&&" and "&"?
&& is a short circuit logical AND, this means that if the LHS evaluates to false, the RHS will not be evaluated. In & both the left and right sides are evaluate every time. For || only if the LHS equates to false, then the RHS side evaluated. When | is used, both the LHS and RHS are always evaluated. - Dzone 20 things you should know about strings
- What’s the difference between shallow and deep cloning
Wednesday, 21 October 2015
Java interview questions - level intermediate
This is the second in a series of articles on Java interview questions. These questions start to go into the details and differences of various parts of the language. Knowledge of them demonstrates a greater level of knowledge or experience than with the basics.
Wednesday, 2 September 2015
Software Oxymorons
An oxymoron is a construct that makes no sense because it joins together two terms that contradict one another. In this post we'll look at some you might come across in development projects. I'll grow this article over time. If you have any suggestions, please feel free to message me!
Oxymorons
- Refactoring Story - A story adds customer value, something tangible that the customer can appreciate. Refactoring is changing the implementation of a software system without the knowledge of the users or customers. So we can be either doing a story or refactoring.
- Refactoring Interfaces - An interface is part of the contract our software components and applications provide. Refactoring is changing the implementation without the knowledge of the users or customers. So if we change the contract, the users know about it. We can change interfaces or we can provide new interfaces but its not possible to refactor them.
- Object Oriented Database - these are a niche area of database theory that haven't really caught on in wider industry and they are also an oxymoron. Databases typically need to know a lot about our classes data structures in order to persist the data in a way that facilitates efficient storage and retrieval. Because of need to know the classes data structure, OODBMS break encapsulation, a key principle of object orientation. This places change restrictions and limitations on our software - something OO is supposed to help avoid
Definitions:
- Refactoring - Changing the implementation of a software system, without the knowledge of the users/components that depend on the software system.
- Story - Something that adds tangible customer value.
- Interface - The point of entry to a software system. Could be programatically ie like an Application Program Interface. It could be via the command line or via a Graphical system.
- Object Oriented - Objects are programming entities that exhibit the principles of abstraction, encapsulation, polymorphism and inheritance.
- Database - a software system that allows us to persist data to survive application restart, typically in tables, columns and rows. Columns are generally typed and can be indexed to facilitate faster querying.
Friday, 28 August 2015
Java interview questions - level easy
This is the first of a series of three articles I want to put together around some Interview questions that could be used for interviewing Java developers. In this first article, we will look at easier, basic concepts that should be covered in any introduction to Java programming. So many of the questions will deal with concepts around defining and declaring classes
- What is the difference between an interface and an abstract class?
An interface is just a contract with no implementation. All methods in an interface are public and abstract. An abstract class can have some state and implementation. - What are the main differences between Java and C++?
Java is compiled to platform independent byte code that is interpreted in a virtual machine. C++ is compiled into native binaries that are not portable. Java gives automatic memory management. C++ memory management is handled by the programmer. - What is the difference between a while statement and a do statement?
A while statement may not execute, a do statement is guaranteed to execute at least once. - Explain the main() method in a java program?
What is passed to it and what is its return type? The main method is the starting point for a java application. The return type is void and the arguments to the java application are passed in an array of Strings to the main method. - What's the first thing that happens in a constructor?
The first call of every constructor must be a call to super() or this(), but never both in the same constructor. If you call this(), eventually super() must be called. - What access can classes have?
public or default. protected and private are also only allowed on methods and instance variables. - What modifiers can classes have? abstract, final or strictfp
- What types are allowed to be in a case statement?
byte, char, short, int and enum. In java 7 we can also switch on String - Interfaces allow inheritance so can an interface have protected methods?
No, an interface can only have public abstract methods. Update for Java 8, interfaces can now have default method implementations. - Java concept of the day 25 basic questions
- Java concept of the day
Monday, 10 August 2015
Object Oriented Design
This short article revisits the first principles of Object Oriented Design
Updated 22nd October, 2015 - clarified coupling, added a statement on dependency. Updated 13th November, 2018 - Spelling mistake corrections
- Why is OO design better than normal procedural coding languages like Bash or C? There are a few reasons. Application code structure and naming should map more readily to real world concepts. Object Oriented design lends itself to more naturally cohesive components (related data and methods are collocated). Thanks to encapsulation, we can reduce coupling. Through the concepts of polymorphism and inheritance we can promote reuse.
- Explain encapsulation? The state of an object should be hidden and only manipulated by methods. The advantage here is that it allows the implementation with in the object to be changed over time without impacting components that depend on this component.
- What is inheritance? Classes can automatically obtain the functionality and state of a parent class. This is also known as sub classing. Inheritance is usually applied for "is a" type relationships. For example if the base class is Car, Corolla is a type of car so Corolla extends Car and automatically gets it's methods and state.
- What is polymorphism? This means where a parent class is used we can easily interchange objects of a sub class. For example if if we have a container that holds objects of type Car, then instances of Corolla and Golf can be added to the container. Polymorphism works best when you understand the Liskov Substitution Principle.
- Explain the concept of dependency? Dependency means that a relationship exists between one or more components. Dependency can be explicit or direct, for example an import statement at the top of a Java class definition. Or Dependency can be implicit or indirect for example two components know the format of an XML document. Generally we favour components that have a lower number of dependencies on other components. And we favour explicit dependencies that are loosely coupled. Coupling is used to classify the strength of the dependency.
- Explain the concept of Coupling? Coupling is the measure of the dependency relationship between two components. Coupling can be tight, where a change in a class has a knock on change in another class. For example Where a component depends on the internal data fields of another component. Loose coupling means that a component depends on behaviour of another component.
- Should software components be tightly or loosely coupled? Good software components should favour loose coupling. In loose coupling, components depend on methods of other components. This means the internals of a component can be changed in isolation - once the contract on the interface is maintained. Tight coupling means that data fields or structure can't be changed in isolation of other components.
- Explain cohesion? Cohesion is how logically related are software elements that are contained with in a software component. Highly cohesive components are better. Low cohesive components should be split into further components to promote reuse and reduce coupling.
- Are getters and setters "evil"? Short answer yes. Because it breaks encapsulation. Breaking encapsulation means your class is less maintainable in the future. Exposing state to other classes means other classes can contain logic that manipulates the state. Go here for a good exploration of this concept. Systems that use getters and setters are object based, but not object oriented.
Updated 22nd October, 2015 - clarified coupling, added a statement on dependency. Updated 13th November, 2018 - Spelling mistake corrections
Monday, 13 July 2015
The test first attitude
Problem statement:
I want to ensure a number is between the range of 5 and 9, inclusive.Thinking in Test first.
I can produce 5 test cases for this very simple problem.A test of a number less than 5. 2. Returns false
A test of the left bound. 5. Returns true
A test of a number in the middle of the range. 7. Returns true.
A test of the right bound. 9. Returns true
A test of a number greater than 9. 15. returns false

Taking a step back, we want to be really thorough we could write the following tests as well.
A test just outside the left bound. 4. False
A test just inside the left bound. 6. True
A test just inside the right bound. 8. True
A test just outside the right bound. 10. False
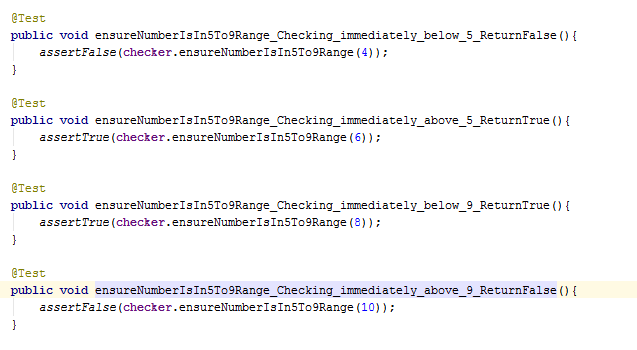
I define an interface to the method.
public boolean ensureNumberIsIn5To9Range(int numberToTest);
First I code up the 9 tests against the specified interface.
Execute all tests. They fail.
Now I start the solution code... I'm done when all tests pass.
I come up with a pretty standard if statement, using logical And and two return statements. The tests all pass.

However now I realise I could make this more concise and prettier for the reader. So I refactor the code to just use logical AND and simply return what it evaluated to the caller. Tests all pass.

Happy days.
Now I check the code coverage, just to be sure it meets targets. 100%. I'm done. Check the whole lot in.
Thinking in solution first approach
I'm going to promise to do some tests to get us code coverage, with a code coverage metric target of 80%. Management love code with a coverage of 80%.I will just code up a if statement, with two boundary clauses anded together. Simple. Will then write a test that triggers the boundary clause. And another test that doesn't trigger the boundary condition so happy out.
Next I'll have a think about the interface, it's gonna be pretty simple in this case.
Open up my IDE. Fire in the interface, the algorithm and now I'll think about tests.

So looking at my code, I can see the branch (if statement). The first test I write, just takes any number outside the boundary condition. So I trigger the method with 15, expecting false. I run it, its passes and I get 75% code coverage. Wow I'm nearly there with just one test!
If I trigger the boundary condition on the if statement, then I can increase this figure. So I'll write one more test. This time I'm going to pass 7. Right in the middle of the boundary condition, I am really expecting it to pass.

I execute it. It passes. 100%!!!!!!! Happy days. Check the whole lot in. Home time.
But wait...
Did you spot the bug in the solution first approach? The upper boundary has been incorrectly coded... values of 10 will return true. It's a good thing this code wasn't used to control an auto mobile safety system, an aircraft or a train!
So I've got 100% coverage, but I'm still leaking bugs. Why?
The set of useful unit tests
We explored the set of useful tests in another article. In this simple example we see the set of useful tests consists of 9 tests. I should implement these 9 tests to ensure correctness of the code. The set of tests that gives 100% code coverage is just 2 tests. This is a significant minority of the tests I actually need to ensure correctness. Hence when reality throws in something we didn't test for, we find bugs, although I have 100% code coverage. You can see there is a large scope for bugs, even in this simple application when you test for coverage.Spending time writing more automated tests around your top 20% of all uses cases that your users use, will give you a much greater bug count reduction in future releases. Spending any time increasing code coverage when you haven't got that 20% of your code base well tested, is waste.
Tuesday, 7 July 2015
Defining a good Unit Test suite
I measure test suites under 6 main criteria. The criteria are pretty hard and fast and there are key indicators to measure them. There is also an AND relationship between them. So if you can tick 5 out of the 6, the other one should be addressed.
- Trust. Tests pass when the component is ok.
- Comprehensiveness Majority of the ways of use for the component are covered by the tests
- Correct level of abstraction. Tests should be written to a stable, well defined interface. Unit tests faciliate refactoring.
- Language Tests should match the language of the problem
- Reliability. Tests fail only when the code is not ok.
- Independent Tests should be independent of other tests, methods and classes, in a pragmatic way. ie each test should only use methods that are "well used" in the public domain. This does not include data driven approaches.
- Libraries Don't test well used and independently verified libraries.
What defines a useful test suite is:
- A developer can be pretty sure, once the unit test suite passes, that no other functional issues will be found. We are happy to release the product after the automated suite passes.
- Majority of the problems are found at the unit-test level. For this our Fault Slip-through Analysis of our bugs indicates that the majority of bugs are found in the right level of test.
- The unit tests are a vital tool to help refactoring. I can do multiple run-test - refactor - run-test cycles, without making a change to the tests. The unit-tests are written towards the "thing" wrapped in an interface, and not just any method or any class.
- They reflect the language of the problem definition re using terminology the customer used. Ideally Customers should be able to understand the tests.
- When a test case fails, it points to an actual problem in the component
- Test cases shouldn't change when we change or extend the system, therefore I can trust them. Test cases are the guarantee that what worked yesterday, still works today. If we have common methods and utility classes referenced in our tests, that are changed as the system grows then we cannot depend on our tests. In other words, if I change my test code, who will test my tests?
- Libraries such as the extensive set of libraries in the JDK, databases like MySql, NEO4J etc are published by competent organisations and are heavily re-used in a lot of software settings. You can trust that their functionally works. Don't write tests that extensively test CRUD of database operations. You can trust that the Collections framework works. You may need to make an exception if you are using pre-release libraries or if they are libraries from your own organisation that you can't trust (i.e. it's your code that is really testing them).
What "smells" to measure that a unit test suite is useless:
- Developers don't trust the unit tests to verify the component. This means, more or less, that a developer isn't that confident to release the component based on unit test alone. We require a manual test before we are confident to release the product.
- Majority of problems are being found in later stages of testing. Our fault slip through Analysis is showing large numbers of bugs appearing in later phases of test, that could have been found in earlier phases.
- The unit tests are written at too low a level and now hinder refactoring. I change the internals of a component and several unit tests no longer compile, never mind that the don't run. Every method of every class has at least one unit test associated with it. Worse still, methods that should be private are public to enable testing!
- They reflect the terminology of the code - we see language of the solution in the tests. For example things like factories or other design patterns start appearing in the tests.
- Test cases regularly fail at random times during various runs. Failures are "false" because they were caused by some environmental or platform problem. For example a database service we needed wasn't started or the disk was full.
- All my tests depend on a test utility method I wrote a good while back and this utility method needs to be regularly changed when we add new features. Most times I add new tests, I have to change the utility method, causing a subtle change in all my tests.
- Lots and lots of tests that test POJO (Plain old java objects), lots and lots of tests that test whether data entry into the database was successful. Often tests are written due to inexperience and a need for coverage metrics. It may be fine to have one test that tests the connection to the database and ensures read/write works, but any more than that is overkill. For POJO's I recommend excluding them from code coverage altogether - there's no logic in there and test cases for the getters/setters are noise.
Updated 26th May, 2016
Updated 3rd June, 2016
Updated 23rd August, 2016
Updated 4th September, 2017
Updated 26th October, 2017
Updated 27th October, 2017
Updated 24th February, 2020
Wednesday, 1 July 2015
The set of useless unit-tests

This diagram depicts the sets of unit tests that exist.
What's immediately obvious is that tests are either considered useful or useless. There is no common ground. It's obvious that the set of useful unit tests is smaller than the set of useless unit tests, but not by much.
Also you can see that you only need a fraction of the tests to get maximum code coverage, the set in blue. This set is a fraction of the total test set in either set.
What's not obvious is that the set of useful tests are more difficult to write because they require a good understanding of the problem. While the set of useless unit tests is relatively easy to develop because they require an understanding of the code. For most developers, it's far easier and less hassle to focus on the code, as opposed to the problem we are trying to solve.
If you just mandate developers to write unit tests, without much support from the people who specify the problem - inevitably they will end up writing tests from the set on the right. These tests, while you think you want them, are pure waste. Extra lines of code. At worst you have to maintain them and at best have to be aware of...
If you then mandate your developers to target code coverage, they will focus on the subset in blue, in the set on the right. This isn't the worst thing in the world. It means you will write less wasteful tests... thats' not a bad thing. However they are still waste.
If you have developers who are mature and experienced enough to write their tests in the set on the left, then you are really lucky. They are a very rare resource. The more of this set we complete the better. We will have less bugs in the future.
When you set a coverage target when writing great tests, there is a danger you write the least valuable tests. The 80:20 rule tells us that 20% of our code is run 80% of the time by our users. Or that users need just 20% of a component, 80% of their time. Then thinking of our users, we need to have tests to verify this 20% of the code base works, all the time. In other words you get most value ignoring 80% of the code base.
So if time is a limiting factor and you are writing good tests, targeting code coverage isn't a good idea because it means that you are writing the least valuable tests.
Wednesday, 27 May 2015
There's a reason standups use closed questions...
Standups, done well, are an important part of a great teams' way of working. Here is a very good article on stand ups its not just standing up
Standups in a nutshell:
To help achieve these goals, typically we let standups revolve around three questions:
One experiment to try and stay on point is to get the team to prepare a (6x4) Q card with the 3 questions specifically answered. Each member then reads out their answers at standup.
Another experiment is to pair up team members. Before standup, each member reports their answers to the three questions to their partner. The partner then relays this at standup.
Standups in a nutshell:
- set a disciplined, defined and energetic start to the day.
- Re focus yourself on your plan for the day
- Re focus the team on the goal for the sprint
- communicate with your team members. Hear what they are doing.
To help achieve these goals, typically we let standups revolve around three questions:
- What did I do yesterday?
- What will I do today?
- What do I need help with?
Getting your team to stay on point
There are a couple of things to try.One experiment to try and stay on point is to get the team to prepare a (6x4) Q card with the 3 questions specifically answered. Each member then reads out their answers at standup.
Another experiment is to pair up team members. Before standup, each member reports their answers to the three questions to their partner. The partner then relays this at standup.
Warning signs and things to try in your standup
- People wandering into problem solving mode in the standup.
Park the discussion. Resume after standup with just the interested parties. - People reporting to the scrum master or the product owner.
Try to report to the whole team. - People not listening to their team members.
Try agreeing a team value. If you are not listening to me, I'm not listening to you. - People joining the standup late and leaving early, once they have given their update.
Discussion with the team member and agreement of a team value to take full part in the standup should help here
Tuesday, 26 May 2015
Team Definitions
In this short article, I want to define and clarify some of the terminology surrounding software teams.
Collection Names
Let's define four collections of people- Group
- Team
- Self organising team
- High performing team
Group
- A number of people who have some common attribute or skill that allows them to be classified together. For example Java developers, scrum masters.
Team
- Defined boundary for the members
- There is a common purpose
- Shared experiences
Self organising team:
- Defined boundary for team members
- Recognized leader
- Subtle control
- Diverse members
- Transforming exchanges
High Performing Team Definition
- Delivering business value all the time
- Will adapt to suit the business
- Continually Improving
- Happy to work together
Wednesday, 29 April 2015
Scrum ceremony cheat sheet
Daily stand up
Purpose: For the team to recommit daily and evaluate where our sprint plan is. Individually each member informs other team members what I am doing and where I can get helpWhen: Daily, in the morning
Who: All team members. PO might be an observer.
Inputs: Sprint backlog up to date to reflect members input.
Output: Everyone knows what everyone else is working on and where they can get help. We know what we need to work on to secure the sprint goal
Sprint planning
Purpose: Set the scope of work for the sprint.When: First meeting of every new sprint.
Who: All team members and PO
Inputs: Groomed and estimated backlog.
Output: A sprint backlog. Sprint started. Commitment from team.
Backlog grooming
Purpose: Adjust the backlog estimates and break up big stories/epics.When: 1-3 times per sprint. 1-2 hours per session
Who: All team members and product owner
Inputs: A selection of X stories from the top of the product backlog
Output: A estimated subset of stories on the backlog. Full backlog will not be costed.
Release Planning
Purpose: Estimate of the size of the backlog on that date.When: half to one full day, every so many sprints
Who: All team members and product owner and coach (optional)
Inputs: Ordered, populated backlog (as much as possible).
Outputs: A fully estimated backlog.
Retrospective
Purpose: Reflect on how we worked in the last sprint so that we can introduce improvements in the coming sprint.When: Last meeting of the sprint, after demo and the sprint is closed.
Who: Team members. Product owner optional.
Inputs: none required
Outputs: Actions for each team member to implement
Demo/Sprint review
Purpose: To show off the teams work and get feedback on work complete.When: At the end of the sprint. 2nd last meeting.
Who: Team members, Product owner. As many other stakeholders as can attend.
Inputs: "Done" stories.
Outputs: A list of feedback from stakeholders on the software just shown.
Updated 15th April, 2016
Monday, 27 April 2015
Great tests are like great wine, great architecture is like great cheese
A great automated test suite is one that allows you to change the internal architecture of the system in any way, with confidence that the system still behaves the same towards its clients after the change is committed. The more the system changes over time, the more the test proves its value over and over again. The older a great test gets, the more value it delivers in facilitating change. So a great test gets better with age. Very much like a great wine.
A great architecture is one that makes the system do what it needs to do and makes it easy and cheap to add many new features. Unfortunately there are always trade offs in the direction of change that an architecture allows. Ultimately the architecture of a product, with some very limited exceptions, becomes the limiting factor in change. In this respect its like a great cheese, it will age well for the first while, but eventually degenerate and rot.
Thursday, 23 April 2015
The -Iliities
In application development, there is a lot of talk about the -ilities. The purpose of this article is to gather a few definitions and explanations of the -ilities together.
Upgrade-ability - the ability to upgrade software, without interrupting service. Can be referred to as "0 downtime" upgrade.
Horizontal Scalability - The ability to increase or decrease capacity of the system by adding or removing instances of services. Ideally, we would like to achieve this without service interruption.
Vertical Scalability - The ability to increase or decrease capacity of the system by adding or removing threads to the running instance of the service. Or to put it another way, how much can the component itself stretch before we have to add more instances of the component.
Availability - The amount of time the service is available to users. Commonly measured % time uptime per year, for example 99.999%. This means the service can be unavailable for a total of 5.26 minutes per year.
Stability - the amount of time the system is running as expected. Less scientific to calculate than availability.
Capability - the list of features that the system/service supports.
Capacity - the load limitations of the system/service. This can be scientifically measured, but different metrics apply for different types of services. For example for certain services the number of operations per second may be important. For other services the amount of data (Bytes per second) processed per second might be important.
Thursday, 26 March 2015
Conversations - What version?
Dev 1: What version of the platform are you using to test your component on your branch?
Dev 2: I'm using version 1.2.3.
Dev 1: Great, I'm also using version 1.2.3.
Dev 2: One thing though. We had to edit the supporting utilities script on the server that was part of the 1.2.3 build. We are waiting for a 1.2.4 build that has the update in it, but it didn't get a green test in CI, so it won't be in the main track today.
Dev 1: So you are not on version 1.2.3, you are on a newer version of software than 1.2.3, that is based on 1.2.3. If I merge in your changes, how can we deliver this to the customer?
Dev 2: We always edit the src on the deployment in order to work around bugs. We usually update the installation instruction afterwards with any of these updates.
Dev 1: I think we need to have a discussion about version control.
Wednesday, 4 March 2015
Coaching v Mentoring v Leading
Coaching:
Helping another person or team or group to attain
higher performance or arrive at a solution. The coach will engage the coached
in a process that helps them discover and arrive at their own solution. The
coach may or may not have actual expertise in the area, it's the disciplined
process that the coach brings to the table. A big aspect of coaching is that
the coached gives the coach permission to coach them. The coach is a
"servant" to the coached. The coached chooses their coach.
Mentoring:
Mentoring:
This is where one party, who has some mastery or
skill or experience, helps another party acquire these skills and experience.
Normally this is done in a one on one situation and using informal means of
teaching for example pairing and peer reviewing and general communication
during day to day work. The mentor pushes their knowledge on the mentored.
Often the mentor is assigned; the mentored has no choice in the matter.
Leading:
Leading:
When a person engages, convinces and motivates
others to follow them. It is a factor of Vision, Trust and Respect. Vision:
where we will get to? The vision attracts people to engage. Trust: People
don't have to be micro-managed or instructed how to attain the
vision. Respect: people are empowered to do what it takes to realize the
vision. Leading should be a push relationship, but the leader needs to create
the environment where followers are willing recipients. There are many bosses
and managers who are not leaders. They have employees, not followers.
Wednesday, 25 February 2015
"Internal" Bugs
Software is full of issues. Tests explore software and uncover some of these issues. Sometimes we won't write enough tests, due to time constraints and reasonable effort already expended. So some of these issues are found by people outside our team - ie our customers.
And its perfectly reasonable of us to provide a bug tracking system for all external stakeholders so they get feedback on their bug as it goes through production.
But why do we record issues we find ourselves, as bugs?
I've often heard that bugs are actually a good thing! It must mean the customer is using our software. Surely the customer is expecting a few bugs. Right?
Wrong. Bugs are bad. Always bad. Every time a customer finds a bug, the effect on our reputation from the customers point of view as software developers is negative. Even if we label the software an Alpha or Beta release just to lower their expectations, they still get a little disappointed when things don't work. Even if we write the bug ourselves before the customer finds it, we still suffer reputation loss. Bugs are expensive in terms of time and money for the customer and we are charging the customer more for they actually already expected.
Analogy: I employ a cabinet maker to make me a new chair. The apprentice and the master craftsman take the measurements, cut the pieces, carve the design and begin the assembly. At one point they figure out that piece X doesn't fit slot X. Do they ring me to tell me that there is an issue? Do they just fix it up? How about when the chair is delivered and I find that it wobbles? There is no difference for software.
So in software development, why do we make public our own sloppiness in what we deliver? Bugs are one indication of sloppiness.
In a scrum team, we must try and establish the culture of honest craftsmanship. If opening the code for a user story, uncovers an issue we need to fix that issue as a task on the story. We must ship a good quality product. So often this occurs right at the end of the sprint. And so often we force ourselves to write the bug, but ship the code anyway. When this happens you have to ask: "Why do we ship sh*t?"
As scrum masters, we need to be disciplined and honest with our team and customers. We are done and ready to ship if we are done and there are no outstanding issues. Otherwise we are not done.
To be true to software craftsmanship and our profession, we need to have a 0 tolerance to bugs.
Tuesday, 3 February 2015
Delivering too early...
This is a transcript of a conversation between 3 developers on a real life project.
Dev 1: OK I have seen what the problem is. My merge wasn't completed like I thought it was and the impacts are missed in the master branch. So it's not in the RPM we delivered.
Dev 3: So lets back out the packages that include your changes.
Dev 1: I really want it to stay in.
Dev 3: Is that really a good idea. It's not tested. It's not really professional to keep it in there, is it?
Dev 1: Ya, well its tested locally and this is valuable feedback for me and the code is finished. You have to crack a few eggs to make an omelet and all that.
Dev 3: OK. Your call.
Dev 1: One other thing, Dev 4 actually made the update to this component. I'm not entirely sure what he did, but there are 4 unit tests failing now. He never updated the unit tests.
Dev 3: OK, so you are still leaving the component in the build? Are you going to remove them or fix them up?
Dev 1: Well I don't know how to fix them up right now. But I'm definitely leaving the rpm in.
Dev 3: So what are you proposing? Commenting out the test cases?
Dev 2: No, we are going to comment out the assert statement at the end of the test case.
Dev 3: ???WTF? So the tests will just pretend to pass?
Dev 2: we want to keep the coverage value high.
Dev 3: <Insert swear word here> lads, that can't be the right thing to do.
Dev 1&2: Code coverage is watched by management, it can't reduce!
Dev 3: I'm not sure I want to hear this. Not sure whether believing the lie or knowing the truth is better!! [laughter all around]
We see lots of dysfunction above. Dev 1 definitely isn't persevering to take total ownership of the product that they have assumed responsibility for (the person doesn't know how to fix the tests correctly). Dev 2 has probably suggested the worst possible solution to the failing tests problem, because he wants to make sure the teams' product code coverage statistic doesn't decrease as it's being watched by management (but he is doing it in a very unprofessional way). Dev 3, on the face of it might look like the best guy here, but that person hadn't the bravery to make sure the right thing is done. Dev 4, the guy who actually made the original code has ignored valuable test feedback, either by not running or ignoring the failing tests.
Ultimately we have three developers who come to the wrong conclusion, despite having the right conversation. There is little excuse for not backing out the package and re-introducing it to the main delivery when all testing is satisfactorily complete, either by Dev 1 or Dev 4. The main track delivery is not the place to be getting initial feedback.
It's interesting is that the management code coverage target drives probably the worst possible behavior with unit-tests - False positives just to keep a coverage figure. When coverage is a target, you have to work hard on the culture of your developers.
Tuesday, 6 January 2015
A brief look at component based teams...
This is an expression of my observations of the challenges I see teams facing.
For our organisation to be agile, we have an explicit need for the "Vertical slice" team. Where every team can make updates across the system, pretty much independently of other teams. Nothing, or at least no other team, gets in the way of progress of the "Vertical slice" team! But in the real world we often shy away from the Vertical team from both a line management and a technical leadership point of view and we continue to form component based teams.
For our organisation to be agile, we have an explicit need for the "Vertical slice" team. Where every team can make updates across the system, pretty much independently of other teams. Nothing, or at least no other team, gets in the way of progress of the "Vertical slice" team! But in the real world we often shy away from the Vertical team from both a line management and a technical leadership point of view and we continue to form component based teams.
Management are tasked with staffing teams with enough competence to get the job done. When focusing on a component, it is far easier to tick competence boxes on the fewer technologies. Also certain in vogue technologies' developers command a kings ransom. It's just financially impossible to have one of those guys in every team.
For developers, the "money" is in being an expert in whatever technology is currently "hot", so developers have a inherent incentive to become an expert in relatively few technologies. The best way to become an expert is to focus entirely on that technology.
The component based team:
The component based team:
Pros
- The most "natural" way for most organisations to setup its' teams.
- Scope of the teams' responsibility is small so they have excellent technical focus. There are a few technologies that the team works intimately with, all the time. Line mgt and developers are happy.
- Team members can become true experts in an area or technology.
- Can build out a "complex" component out of sophisticated "niche" technologies relatively quickly.
Cons
- That team only knows a small part of the system. They are effectively limited to working on that part of the system.
- The team can have the illusion of being successful in a product that is failing
- There is a big "tax" when moving people or other teams onto or off this component.
- Those people become key to the organization even though they might not be domain experts in the business. The team can make themselves indispensable to the organisation.
- Component becomes impossible to fundamentally change its technology as the business changes. A component team is loyal to the technology because they have so much expertise. The business adapts its solutions to fit the technologies employed.
- Long term waste/expense. Over medium to long term you end up building parts of a component that are "nice to have" and may never be used by the business.
- Perceived "God" complex develops over time. And Conways' Law applies.
Monday, 5 January 2015
Happy new year 2015
Its been a while... Had a busy 6 months since my last post. With the new year and all that I'm back and will be creating some articles. The main aim of this blog is to share some observations and knowledge, while re-enforcing my own learning.
The aim is at least 1 per month, as per last year. While I haven't been publishing, I have been gathering some ideas for articles. I hope to add some book and video reviews as I go.
Looking forward to a great 2015.
The aim is at least 1 per month, as per last year. While I haven't been publishing, I have been gathering some ideas for articles. I hope to add some book and video reviews as I go.
Looking forward to a great 2015.
Subscribe to:
Comments (Atom)